검정력을 확보해야 하는 이유
요약
관찰된 효과의 크기가 통계적으로 유의하더라도 (p-value < 0.05)
실제 효과보다 과장 되었을 가능성이 있으며 검정력이 낮을수록 과장의 정도가 심해진다.
A/B 테스트는 사전에 정의된 평가지표(primary metirc)에 대해 최소 샘플 사이즈가 확보된 이후,
단 한번의 통계적 검정으로 실험의 효과 유무를 판단하는 것이 이상적이다.
하지만, 왜 충분한 수준의 검정력(Power)을 확보해야 하는 것일까?
일차적인 이유는 검정력의 정의에서 알수 있다. 검정력은 ‘각 변형 간에 의미 있는 차이가 있을때 이를 감지할 확률로’ 정의되는데
이는 검정력이 낮은 상태에서 통계적으로 유의미한 결과를 얻을 경우, 우연에 의한 결과일 확률이 높아지기 때문이다.
(또는 Power = $1 - \beta$ 라는 관점에서, ‘2종 오류’를 줄이기 위해서라는 이해도 가능하다)
그렇다면 또 다른 이유는 무엇일까? 그건 바로 효과의 과대 추정을 방지하기 위함이다.
아래의 그래프는 검정력의 크기에 따른 과장 비율을 도식한 그래프로 (Gelman & Carlin, 2014)
업계 표준인 검정력 80%에서도 약 13%의 과장이 발생하고, 50%에서는 40%의 과장, 10% 이하에서는 약 400% 이상의 과장이 발생하는 것을 알 수 있다.
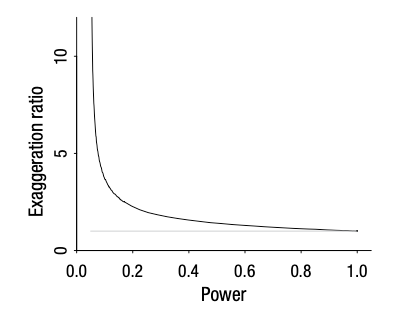
- Exaggeration ratio(과장 비율): 효과가 통계적으로 유의미하게 0이 아님으로 나타났을 경우,
추정된 효과 크기의 절댓값을 실제 효과 크기로 나눈 값의 기댓값
이와 관련해서는 Ron 박사님 역시 다음과 같이 언급한 바 있다.
At 80% power, which is the industry standard power for a well-run experiment, the exaggeration factor is 13%. This may not seem like much, but when you add up successful experiments from the last year and tell finance that they added up to 15% improvement to conversion or revenue, make sure to apply at least this haircut and report 13%. I wrote “at least” because due to multiple-hypothesis testing (we often run A/B/C/D tests) and other human degrees of freedom, I would haircut at least 20%, the number we used at Bing.
따라서 우리는 실험 설계 및 평가시, 최소 샘플 사이즈확보가 평가 결과의 신뢰성 확보에 훨씬 더 많은 영향을 준다는 것을 인지할 필요가 있다.
References
[1] Gelman, A., & Carlin, J. (2014). Beyond power calculations: Assessing Type S (sign) and Type M (magnitude) errors. Perspectives on Psychological Science, 9(6), 641–651.
댓글남기기